
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- abstractclass
- Polymorphism
- fuction
- run()
- overload
- class
- eclipse
- methodArea
- object
- constantnumber
- ALTER
- Vector
- garbagecollection
- 객체형변환
- 콘크리트클래스
- reference
- 생성자
- 추상클래스
- hashCode
- override
- MSA
- Hashtable
- start()
- Eureka
- super
- hamobee
- string
- concreteclass
- arguments
- value
Archives
- Today
- Total
뇌운동일지
[hadoop] window환경에서 hadoop 실행 본문
기본적인 사용 설정은 되어있다는 가정
1. hadoop-2.6.0_64x.zip을 압축을 풀어서 사용 위치에 저장

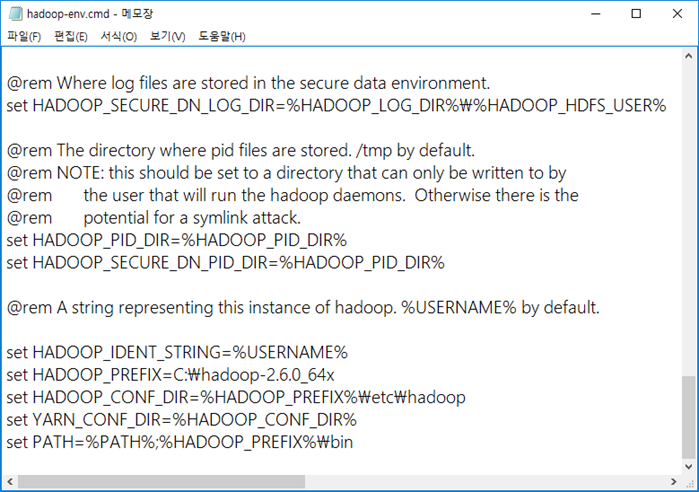
2. hadoop-env.cmd 문서에 수정내용 기입


3. hdfs 설정을 위해 namenode 포맷

4. 하둡 시스템 권장 모드로 시작

두 가지 명령을 실행하면, 아래 4개의 창이 나온다.

5. 하둡 파티션에 /big 저장소 생성

6. 하둡에 저장할 소스 bigdata.txt 를 생성, 하둡 파티션 /big 에 저장


이렇게 bin 아래에 분석할 txt 파일과 hadoop-mapreduce-examples-2.6.0.jar 를 옮겨준다.
파일을 옮겨주지 않으면 full 경로를 입력해야 하는데, 번거로우므로 그냥 옮겨준다.

7. hadoop-mapreduce-examples-2.6.0.jar 예제를 찾아서 /big 데이터를 분석, /out 에 출력하는
wordcount를 실행

8. 실행 결과 part-r-00000 을 읽어서 화면에 출력

9. 하둡 파티션 출력 폴더로 사용한 /out 폴더 전체(파일,하위포함)를 삭제하고 확인

10. 하둡 권장 모드로 종료

11. 분석모듈 wordcount용 mapper

맵은 raw 데이터를 받아와서 key, value로 바꾸는 작업.
매퍼클래스 상속받음
LongWritable, IntWritable 은 하둡 전용 자료형, String 은 Text 로 사용
( 전송 가능하게 바이트 별로 보내는 솔루션 내장 )
인풋으로 key, value가 들어오고, 아웃풋으로 key, value가 나감.
12. 분석모듈 wordcount용 reduce

reduce 는 map 에서 묶은 key, value 쌍을 이용해서 나에게 맞는 key, value로 재조립
reduce 는 중복된 키를 처리
맵의 output 이 reduce의 input
13. 분석모듈 wordcount용 driver

드라이버에는 자바를 실행시켜줄 main 함수가 들어있다.
'BigData > Apache Hadoop' 카테고리의 다른 글
| [Hadoop] 개념정리 (0) | 2021.08.02 |
|---|---|
| [hadoop] hadoop 연습 (0) | 2020.06.29 |
| hadoop 연습 (0) | 2020.06.24 |
'BigData/Apache Hadoop' Related Articles
more



Comments