
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- class
- arguments
- string
- 추상클래스
- ALTER
- concreteclass
- Vector
- MSA
- reference
- overload
- hashCode
- abstractclass
- fuction
- methodArea
- constantnumber
- Polymorphism
- super
- 객체형변환
- garbagecollection
- 콘크리트클래스
- eclipse
- object
- Eureka
- override
- value
- hamobee
- start()
- Hashtable
- run()
- 생성자
- Today
- Total
뇌운동일지
[ R ] 빅데이터 분석 결과 시각화 본문
2015년 한국복지패널 통계 자료를 로드한 후 성별 평균 임금 차이가 있는지 분석한 후 시각화
우선 install.packages() 로 필요한 패키지를 설치해야 한다. installed.packages() 로 확인해본 결과, 이미 설치되어 있으므로 넘어간다.
사용할 패키지를 로드한다.


데이터 프레임을 생성하고, 복사본을 만든다. 원본 데이터에 변화가 생기지 않도록 복사본을 만드는 것이다.


R studio에서 가져오는 파일의 위치를 볼 수 있다.

데이터를 확인해본다.


결과가 너무 많으므로 아래는 생략한다.

View(welfare) 를 실행하면, 이렇게 볼 수 있다.



분석에 편리하도록 각 컬럼마다 이름을 지정해준다.


성별과 관련된 데이터를 전처리한다.


sex column 의 데이터형은 numeric 이고,
1, 2 두 가지 종류가 있다. 데이터의 양은 첨부한 결과와 같다.


결측치가 있는지에 대한 명령의 결과가 모두 FALSE 이므로 결측치는 없다.




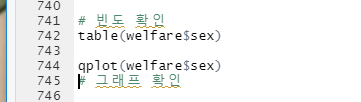
table() 로 빈도를 확인하고, qplot() 으로 그래프를 확인한다.


수입 데이터를 전처리한다.



위의 그래프에서 1000 이상에서는 데이터가 적으므로, x축의 범위를 1000이하로 제한해본다.




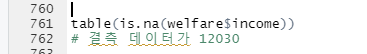
여기서 TRUE 는 결측치를 말한다.


이상치 제거 전의 값과 비교했을 때 TRUE에 해당하는 값이 증가했다.
사용할 수 없는 데이터가 있다는 의미이다.


welfare 에서
income 이 na 가 아닌 값들만
sex 로 묶어서
income 의 평균값을 구해서
sex_income 에 대입


남성의 평균 임금이 더 높다는 것을 알 수 있다.
'R' 카테고리의 다른 글
| [ R ] 빅데이터 수집 시스템 개발 (0) | 2020.08.03 |
|---|---|
| R 설치 및 셋팅 (0) | 2020.06.30 |

