
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- run()
- eclipse
- value
- MSA
- fuction
- 콘크리트클래스
- object
- Vector
- Polymorphism
- class
- methodArea
- abstractclass
- string
- constantnumber
- garbagecollection
- Eureka
- hamobee
- super
- 객체형변환
- overload
- hashCode
- ALTER
- reference
- 생성자
- concreteclass
- override
- arguments
- Hashtable
- start()
- 추상클래스
- Today
- Total
뇌운동일지
Elasticsearch CRUD 본문
강의를 참고
https://dev-youngjun.tistory.com/75
Index -> RDB의 데이터베이스
Type -> RDB의 테이블
Document -> RDB 테이블의 Row. Json 문서로 되어있음 (key, value)
Field -> RDB 테이블의 Column. ElasticSearch의 문서는 Json. Json의 property는 ElasticSearch에서 Field
1. class senario
PUT -> index 생성
GET -> index 조회
DELETE -> index 삭제



UPDATE
Document에 Field 추가

기존 Field 값 변경

script 로 기존 Field 값 변경

bulk data insert

id 1,2 번의 data 확인

index 삭제, 생성, 확인

mapping 으로 data type 지정


2. basketball scenario
bulkdata insert

search
search option 없을 때 -> 전체 데이터 출력

_search uri옵션으로 points가 30점인 data 가져오는 query

_search request body 사용.
term query 로 points 30 인 데이터만 반환

Metric Aggregation
Aggregation : ElasticSearch 내의 Document 조합을 통해 값을 도출할 때 쓰임.
Metric Aggregation : 산술에 사용
avg aggregation : 평균 구하기


max aggregation

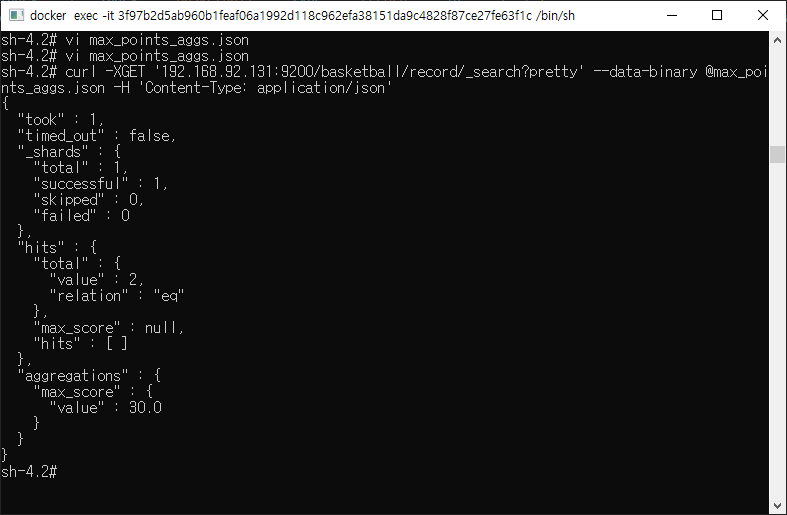
min aggregation


sum aggregation


stats aggregation


Bucket Aggregation
group by 의 역할
mapping 시키기 위해 basketball index 삭제 후 다시 생성

basketball_mapping.json

"fielddata" : true -> aggregation 할 때 조회 true
mapping을 elasticsearch에 적용

sampledata bulk insert

Term Aggregation
group by team

"size" : 0 -> 다른 여러 정보를 표시하지 않고 결과만 도출
players -> Aggregation 이름
terms -> term Aggregation 을 사용한다고 정의

현재 sample data 에서 document 1,2 번은 chicago 팀. document 3,4 번은 la 팀.
팀 분류하고, 팀 별 성적 확인하기


TroubleShooting )

-> json 파일의 마지막줄에 newline 넣어주어서 해결
csv to json 으로 변환해서 직접 넣어줌. -> 잘 안되었다.

'purple duck 일지' 카테고리의 다른 글
| Elasticsearch : kibana 로 csv data import 하고, 데이터 조회해보기 (0) | 2021.10.18 |
|---|---|
| mongoDB (0) | 2021.10.15 |
| Elastic Search : docker에 elasticsearch 설치, logstash 실행하려 했으나 해결하지 못한 과정 (0) | 2021.10.12 |
| Vue.js + express 에서 알림서비스 : email, slack, kakaotalk (0) | 2021.10.07 |
| Vue.js + express 탐구생활 (0) | 2021.10.06 |

